2023년 넷플릭스 수익: 성장과 전망
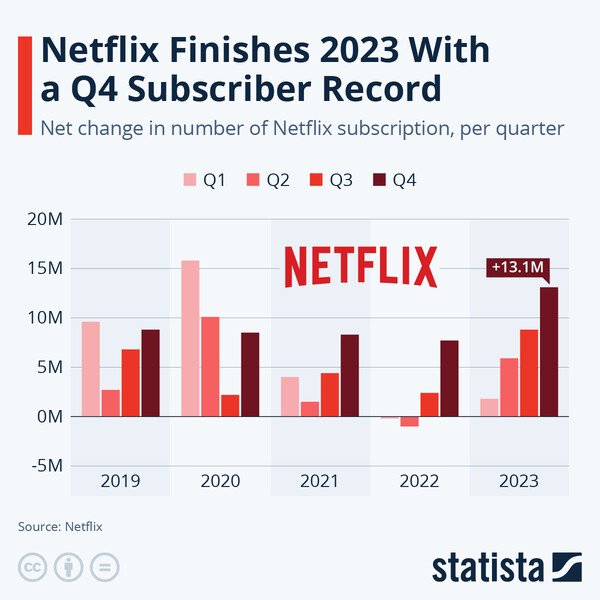
2023년 넷플릭스 수익: 넷플릭스는 최근 몇 년 동안 스트리밍 서비스 시장에서 주도적인 위치를 차지하고 있습니다. 많은 이용자들이 다양한 콘텐츠를 쉽게 즐길 수 있는 편리함과 다양한 옵션을 제공하는 넷플릭스는 2023년에도 높은 수익을 기대할 수 있습니다. 넷플릭스 무료 https://onlytv6.com/ 넷플릭스의 성장과 수익 넷플릭스의 역사와 성장 넷플릭스는 1997년에 설립된 이후 지속적인 성장을 거듭해왔습니다. 초기에는 DVD 대여 서비스로 시작하여, … Read more
